Recall(From the intro post)
WordBridge splits responsibility across an Interaction Model (fast, real-time detection and delivery) and a Background Model (slow, contextual reasoning and safety decisions). That split isn't a new idea — it's a specific application of a pattern that's showing up across AI research right now. Worth looking at where it comes from and where it's been stress-tested before assuming it transfers cleanly.
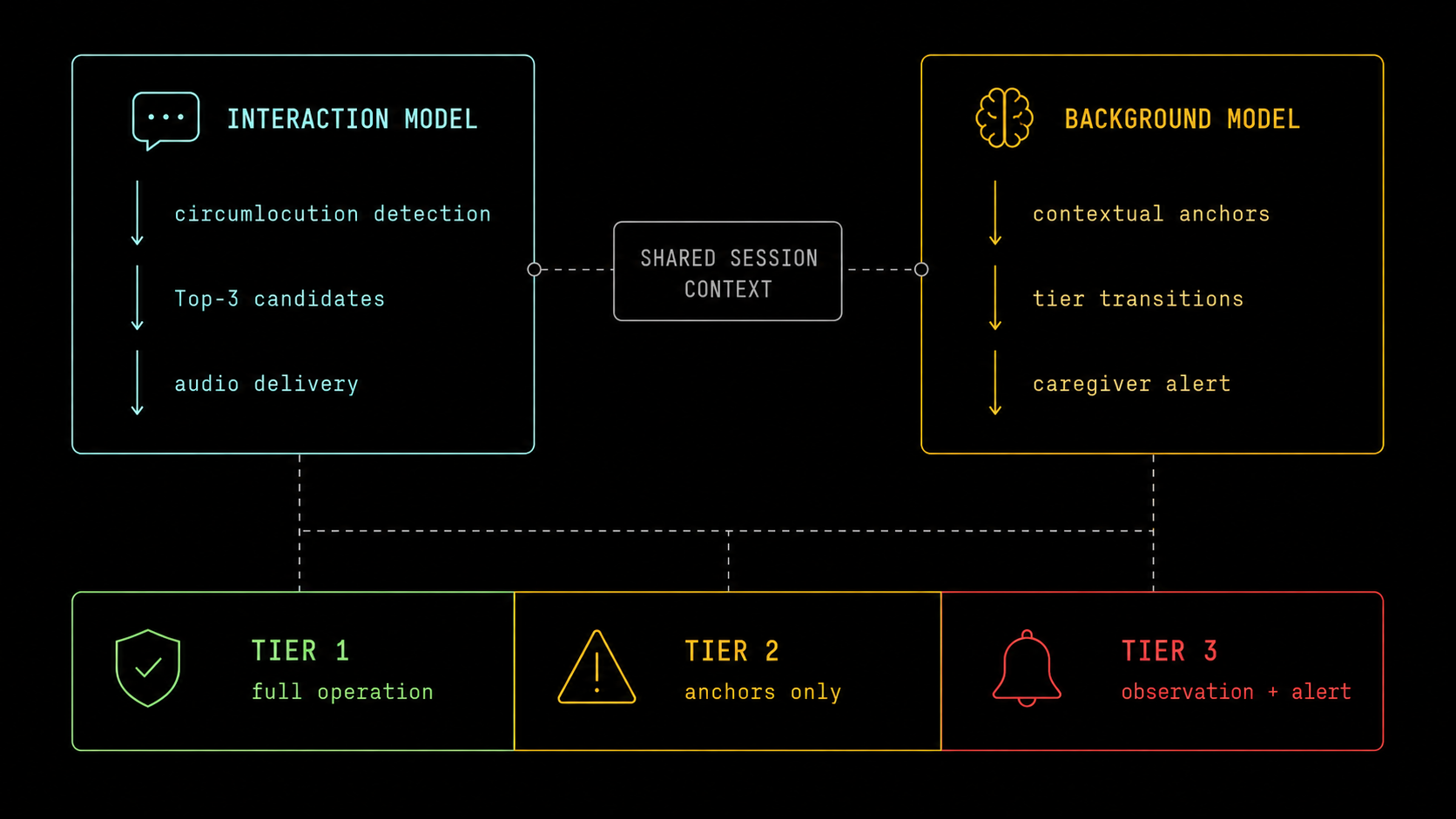
The pattern has a name, and it's everywhere right now
The fast/slow split maps onto the old "System 1 / System 2" framing from dual-process cognitive psychology — a quick, reactive process and a slower, deliberative one — and 2025–2026 has seen it adopted across several unrelated corners of AI research:
- Robotic manipulation — Fast-in-Slow keeps an intact vision-language model for System 2 reasoning, then repurposes its final transformer blocks into a System 1 execution module for low-latency motor control, so the fast path inherits the slow model's pretrained knowledge instead of being a separate small model (arXiv:2506.01953).
- Dialogue planning — DPDP pairs a fast policy-based model (System 1) with a slow MCTS planner (System 2), switching between them based on the policy's own uncertainty.
- Continual agents — a System 1 retrieves compact context from long-term memory and responds, while System 2 reflects on outcomes afterward and writes curated updates back into memory.
Intuition(Why this keeps reappearing)
Every one of these is the same shape: a fast path that can't afford to "think," and a slow path that can't afford to be "live." The dual-model split isn't a WordBridge-specific design choice — it's what you get whenever a system needs both sub-second reaction and multi-minute context, and a single model can't be tuned for both at once.
TML-Interaction-Small, with actual numbers
The intro post cited Thinking Machines Lab's interaction model blog post in general terms. The concrete numbers behind it:
TML-Interaction-Small is a 276B-parameter mixture-of-experts model with 12B active parameters, built for full-duplex operation — processing ~200ms of input while simultaneously generating ~200ms of output, in an interleaved multi-stream design (Thinking Machines Lab, DataCamp).
Definition(Full-duplex (in this context))
A model that can process incoming audio and generate outgoing audio at the same time, rather than waiting for one party to finish before the other starts. The opposite of turn-based: both directions of the "conversation" are live simultaneously.
On published benchmarks:
| Benchmark | What it measures | TML-Interaction-Small | Comparison |
|---|---|---|---|
| FD-bench V1 | Response latency in conversational turns | 0.40s | Gemini-3.1-flash-live (minimal reasoning): 0.57s; GPT-Realtime-2 (minimal reasoning): 1.18s |
| FD-bench V1.5 | Handling interruptions, "uh huh" interjections, foreground vs. background speech | 77.8 avg quality | GPT-Realtime-2 (xhigh reasoning): 47.8; Gemini-3.1-flash-live (high reasoning): 45.5 |
| TimeSpeak | Time-triggered speech generation — does the model speak at the right moment? | 64.7% macro-accuracy | Internal benchmark, no public comparison |
| CueSpeak | Semantically-timed speech — does the model wait for the right semantic cue before responding? | 81.7% | Internal benchmark, no public comparison |
The FD-bench V1.5 numbers matter more for WordBridge than the raw latency figure. WordBridge's entire delivery mechanism — a word candidate delivered through the user's audio output while they're mid-sentence — is an interjection into foreground/background speech. That's the exact scenario FD-bench V1.5 is built to evaluate, and it's the dimension where TML-Interaction-Small's published lead over competitors is largest (roughly 30+ points), not just the latency dimension.
The closer analog: proactive agents
Latency benchmarks tell you the model can respond fast. They don't tell you whether it knows when it should. The more relevant work here is ProAct, a dual-system framework for proactive embodied social agents — agents that initiate interaction rather than only responding (arXiv:2602.14048).
ProAct splits into:
- A Cognitive System — reasons about social context and decides whether and when to initiate
- A Behavioral System — executes the actual motion/gesture/expression once that decision is made
This is structurally identical to WordBridge's Background Model (decides tier transitions and whether an anchor/suggestion should fire) and Interaction Model (executes delivery). ProAct reports that this separation improves both the decision quality and the naturalness of execution compared to end-to-end approaches — which is some independent evidence that WordBridge's safety-framework split (Section 3.3 of the proposal) isn't just a clean abstraction, it's a pattern that's already shown measurable benefit elsewhere.
Note
ProAct's "initiate interaction" is between the agent and the person it's talking to. WordBridge's "initiate" is the agent inserting itself into a conversation between two other people (the patient and whoever they're talking to). That's a different social topology — nobody asked the agent to be part of this conversation at all. None of the proactive-agent literature I found addresses this third-party framing directly.
Where the pattern might not transfer
Warning(Interruption handling is still an open problem)
FLEXI, a benchmark specifically for full-duplex human-LLM speech interaction, finds that even current full-duplex models "struggle substantially with genuine overlapping speech" and that most systems were fundamentally designed for turn-based interaction despite full-duplex framing (arXiv:2509.22243). Naturalness in concurrent-speech scenarios is, per FLEXI, "largely unachieved" even at the frontier.
WordBridge's core mechanism — delivering a word candidate while the patient is actively speaking, without derailing them — is precisely this unsolved case. TML-Interaction-Small's FD-bench V1.5 lead is encouraging, but FD-bench V1.5 measures handling interruptions in a two-party human-AI conversation. WordBridge needs the model to insert audio into a human-human conversation it's only overhearing — an even less-studied variant.
This doesn't break the proposal, but it does sharpen what the prototype actually needs to validate first. The dual-model split (Section 3) and the safety-tier authority division (Section 3.3) both have reasonable analogs in the literature with measurable benefits. The thing with no analog — and the thing H2's 500ms/1s/2s latency windows are really testing — is whether an interjection into an overheard conversation lands as "helpful aside" rather than "interruption," at timescales where the difference is a few hundred milliseconds.
Summary(Summary)
The interaction/background dual-model split is a well-established pattern (Fast-in-Slow, DPDP, continual-agent memory systems) and TML-Interaction-Small has real benchmark numbers backing the latency and interruption-handling side (FD-bench V1: 0.40s; FD-bench V1.5: 77.8 vs. ~46-48 for competitors). The closest analog to WordBridge's safety-tier authority split — ProAct's cognitive/behavioral division for proactive agents — shows measurable benefit from exactly this kind of separation. The open question is narrower than "does the dual-model pattern work": it's whether inserting audio into an overheard human-human conversation, at sub-second timing precision, behaves like the interruption-handling cases that have been benchmarked so far. FLEXI suggests that even the two-party version of this problem isn't solved yet.